Если вы сразу вспомнили о победах AMD EPYC или Ryzen в CINEBENCH и решили, что здесь все понятно, то не торопитесь — работа над CG-эффектами и анимацией в реальности не так проста, а наличие нескольких ядер все равно ничего не решает. При поддержке московского офиса AMD, дистрибьютора ASBIS и студии CGF мы подготовили материал о тонкостях студии и ее опыте пробной эксплуатации новых процессоров AMD EPYC 7002 серии, который студия протестировала для оценки возможности их дальнейшего использования в серверном парке.
В студии сотни работ — от спецэффектов для полнометражных фильмов до короткометражных рекламных роликов, а также полностью анимационных картин. Однако даже так называемые VFX перерывы, из которых зритель узнает, что было реальным, а что нет, не в полной мере отражают глубину и сложность создания даже нескольких захватывающих секунд видео, на создание которых в реальности могут уйти часы или даже дни. Невозможно будет рассказать обо всех тонкостях и нюансах, потому что у студии есть свои секреты, но можно получить общее представление о процессах.
Рабочий процесс
Типичный сценарий работы студии над спецэффектами для фильма нелегко описать, потому что все зависит от конкретного проекта. В общем, задача состоит в обработке исходного съемочного материала — добавлении в него недостающих объектов, удалении лишних или исправлении отснятых. Исходный видеоматериал со съемок может состоять из десятков терабайт данных. Как правило, такой видеоматериал хранится на наборе лент LTO. Наряду с увеличением емкости лент, растет и качество видео, его разрешение и глубина цвета, поэтому одна кассета LTO-5 размером 1,5 терабайта может выдержать всего 5-10 минут записи (без сжатия).
В самом сложном случае всё начинается с оцифровки физических или моделирования будущих "искусственных" объектов в кадре, а также моделирования, т.е. физических расчётов поведения и взаимодействия таких объектов. Затем следует рендеринг — отрисовка смоделированных объектов. Композитинг — совмещение вычисленных и нарисованных объектов с исходным видео в самом конце. За таким формально простым описанием, конечно же, скрываются десятки часов работы большого количества специалистов.
Графические станции используются для начального моделирования объектов, в основном из Autodesk Maya. За моделирование, физические расчеты, рендеринг и т.д. отвечает SideFX Houdini. Для создания композиций студия использует The Foundry Nuke. Для каждого программного обеспечения имеются отдельные дополнительные плагины и модули. Кроме того, есть свои собственные локальные инструменты. Каждая стадия разделена на отдельные задачи, модули достаточно независимы друг от друга по вычислениям. Практически все эти задачи попадают на рендер-ферму.
*"Проблема многих небольших голливудских студий заключается в ограниченном бюджете на приобретение новых серверных ферм и рабочих станций. А в случае с CGF, цикл обновления оборудования, все достаточно дешево, может составлять от 4 до более 7 лет. Для экономической рентабельности, качества работы и скорости выполнения заказов студии необходимо максимально эффективно использовать все существующее оборудование", — отмечает Кирилл Кочетков, технический директор студии CGF, под чьим руководством проводились испытания новых платформ.
В результате, рендер-ферма CGF не является полностью унифицированной, она состоит из нескольких типов когда-то дорогих лопастей и серверных систем. В свободное время отдельные графические станции сотрудников также подключаются в качестве дополнительных узлов фермы. А при выборе нового "железа" важно подбирать процессоры и платформы под конкретную нагрузку и поддерживать баланс, так как задачи, описанные выше, заметно различаются требованиями к ресурсам: однопоточность и многопоточность, ядро IPC, пропускная способность памяти и так далее.
Многие задачи моделирования очень ресурсоемки — время счета на кадр может составлять несколько часов. В то же время существуют как скрипты, использующие все ресурсы процессора (8-24 потока), так и специфические задачи, которые фактически используют только один поток и для которых на первый план выходит частота и IPC одного ядра. К ним относятся некоторые физические вычисления, где каждое следующее состояние напрямую зависит от предыдущего — например, распад объекта на части с последующим их взаимодействием между собой и с окружающей средой, на которое они также влияют. В среднем, рендеринг сам по себе достаточно хорошо параллелен.
Для большинства задач в основном используются вычисления на процессоре. В некоторых случаях GPU могут обеспечить ускорение, но это не универсальное решение. При правильном финансировании конкретного проекта некоторые студии строят системы с педалями газа для конкретного программного обеспечения. В случае с CGF, добавление GPU в существующую ферму студии уже не имеет особого смысла в связи с устареванием серверной части и накопленными инструментами.
Вторым важным ресурсом является оперативная память. Его потребление зависит от конкретной задачи (и даже от конкретного кадра), и если его недостаточно, могут возникнуть дисбалансы и замедление работы в целом. В частности, задача может потреблять почти всю оперативную память узла, обременяя лишь малую часть имеющихся ядер. Наконец, время счета увеличивается в несколько раз по окончании работы свободной оперативной памяти узла и приходится использовать файлы подкачки на дисках
Наконец, не забывайте о дисковой подсистеме. Требования к ней также зависят от задач. Некоторые из них требуют большого объема входных данных, но на выходе получается довольно небольшой. Для других все как раз наоборот (обычно это моделирование физики), а для других результаты промежуточных вычислений занимают огромное количество места, но входные и выходные данные относительно малы. Другой нюанс заключается в том, что распространенные технологии кэширования не эффективны в большинстве задач, так как файлы обычно читаются только один раз. Некоторые алгоритмические вычисления могут выполняться очень эффективно в облаке или на удаленном кластере, так как нет необходимости гонять десятки терабайт данных на дисках и между узлами и хранилищами.
Для упрощения процесса распределения задач каждый из них имеет определенный вес, который отражает требования к ресурсам. Каждый узел фермы, соответственно, имеет определенную емкость. Если, например, узел имеет емкость 1000 условных единиц (ср. E.), то он сможет обрабатывать десять задач по 100 ср. каждая или две задачи по 350 ср. E. и две задачи по 150 ср. E. одновременно. Но задача из 2000 квадратных единиц уже не сможет справиться с таким узлом, и до него не дойдет.
*"Поддержание баланса доступных и требуемых ресурсов позволяет CGF эффективно использовать доступное оборудование. А если нагрузка распределена не по всей ферме, то это прямая потеря денег из-за простоев или недостаточного использования оборудования. В идеале, вся ферма должна быть всегда на 100% загружена, и на практике именно этого хочет CGF", — говорит технический директор студии CGF.
Render-farm
Ферма CGF на базе лопастей (4U, 10 "лопастей") позволила более плотно расширить вычислительные ресурсы на доступных площадях студии. На данный момент существует две версии таких узлов, основанных на прошлых поколениях Intel Xeon:
- двухпроцессорный "blade" проще, в двух версиях (далее Blades 1 и Blades 2), но с одинаковой конфигурацией: 2× Intel Xeon E5645 (6C/12T, 2.4-2.67 ГГц, 80 Вт), 64 Гб оперативной памяти;
- "blade" проще, также двухпроцессорный (Blades 3): 2× Intel Xeon E5-2670 (8C/16T, 2.6-3.3 ГГц, 115 Вт), 128 Гб оперативной памяти.
Но это еще не все, все рабочие станции в студии используются, когда они свободны от интерактивного использования сотрудниками. Их типовая конфигурация включает 8 или 12 потоковый высокочастотный процессор — Intel Core i7-6700K, i7-8700K или i7-9700K — и 64 ГБ оперативной памяти. Общее количество активных узлов на пике достигает 150.
На ферме запускаются задачи моделирования и рендеринга, расчета модели, а также задачи построения конечного изображения. Программное обеспечение рендер-фермы работает на дистрибутиве Linux Debian 10. Распределение задач выполняется менеджером CGRU, популярным программным обеспечением с открытым исходным кодом для управления рендер-фермой. Так как задач много, и все они относительно независимы друг от друга, ферма готова принять практически любое подходящее оборудование, и всегда есть чем его загрузить.
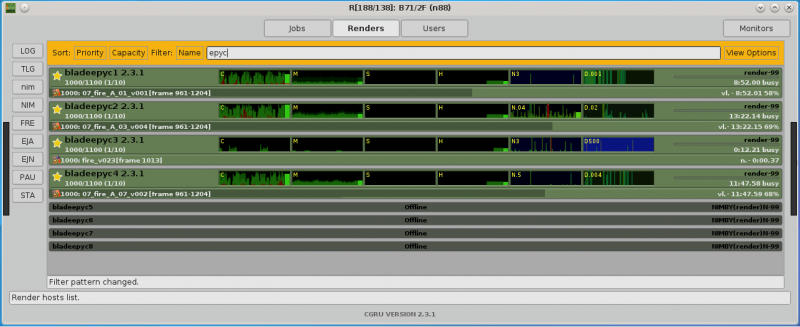
Поэтому мы добавили тестовые серверы на базе современных процессоров AMD EPYC и Intel Xeon Scalable к этой рендеринговой ферме для оценки перспектив использования. Прежде всего, было интересно узнать, как будут выполняться задачи студии на самом современном односокетном сервере AMD с максимальным количеством ядер и двух двух двухсокетных системах с процессорами AMD и Intel с примерно одинаковым общим количеством ядер на машину.
К сожалению, на момент тестирования не удалось получить наиболее похожие конфигурации с новым Intel Xeon Gold 6248R, которые имеют большее количество ядер и более высокую частоту по более низкой цене (1 кюм RCP$2 700), а также новый AMD EPYC 7F72 (1 кю RCP $2 450) с тем же количеством ядер на машину, но с более высокой частотой. В результате были взяты конфигурации с немного более простыми, но более дешевыми процессорами, что с точки зрения стоимости процессора (см. ниже) кажется вполне приемлемым вариантом для тестирования.
Однопроцессорный сервер на базе AMD EPYC 7702 (далее EPYC x1):
- Гигабайт R162-Z11-00 (1U) платформы;
- 1 × AMD EPYC 7702 (64C/128T, 2,0-3,35 ГГц, 180 Вт);
- 512 Гб (8 × 64 Гб) DDR4-3200;
- SSD Seagate FireCuda 520 (М. 2, NVMe, 500 Гбайт);
- сетевой контроллер 10GbE;
- 2 × BP 1200 Вт (80+ Platinum).
двухпроцессорный сервер на базе AMD EPYC 7402 (далее EPYC x2):
- Гигабайт R282-Z91-00 (2U) платформы;
- 2 × AMD EPYC 7402 (24C/48T, 2,8-3,35 ГГц, 180 Вт);
- 1 ТБ (16 × 64 ГБ) DDR4-3200;
- SSD Seagate FireCuda 520 (M.). 2, NVMe, 500 Гбайт);
- сетевой контроллер 10GbE;
- 2 × BP 1600 Вт (80+ Platinum).
двухпроцессорный сервер на базе Intel Xeon Gold 6248 (далее Xeon x2):
- Гигабайт R281-3C2 (2U) платформы;
- 2 × Intel Xeon Gold 6248 (20C/40T, 2.5-3.9 ГГц, 150 Вт);
- 768 Гб (12 × 64 Гб) DDR4-2933;
- 2 × SSD Samsung PM883 (SATA, 240 Гб; LSI RAID);
- 10GbE сетевой контроллер;
- 2 × 1200 Вт (80+ Платина) блок питания.
Все машины работали с профилем производительности, а для AMD оставили по одному NUMA-домену на сокет по умолчанию. На всех машинах был установлен тот же программный стек, что и на ферме; проблем с ним не возникло. На локальных дисках находилось только программное обеспечение, а доступ к рабочим данным на внешнем NFS-накопителе осуществлялся по сети 10GbE. Все машины получили конфигурацию памяти 1DPC с максимально возможной частотой для каждой платформы. Для текущих задач студии, вычисляемых на ферме, такой объем памяти чаще всего является избыточным, но в тестах он, безусловно, не будет являться ограничивающим фактором производительности.
Тестирование
На одной машине каждого типа — EPYC x1, EPYC x2, Xeon x2, Blades 1, Blades 2 и Blades 3 — были запущены одни и те же тестовые сценарии, включающие как исключительно синтетические нагрузки, которые на практике являются лишь частями более крупных задач, так и реальные расчёты тех проектов, над которыми студия работала в течение тестового периода в несколько недель.
Синтетические тесты
Физические расчеты (симуляции) различных типов объектов и веществ в программном обеспечении SideFX Houdini были использованы для первоначальной оценки производительности узлов:
- Ткань — ткань и одежда;
- FLIP — жидкость;
- Зерно — сыпучие материалы;
- Пиро — газ;
- RBD — динамика твёрдых материалов;
- Ткань и Волосы мерцания — динамика мягких тел, основанная на явных связях между точками.
Такие вычисления относительно быстры и имеют различные требования к количеству и частоте ядер. Например, инструмент Cloth имеет однопотоковую природу, поэтому важна только максимальная частота одного ядра. Другие инструменты способны в той или иной степени распараллелить вычисления. В данном тесте на каждый узел приходилось ровно одно вычислительное задание.
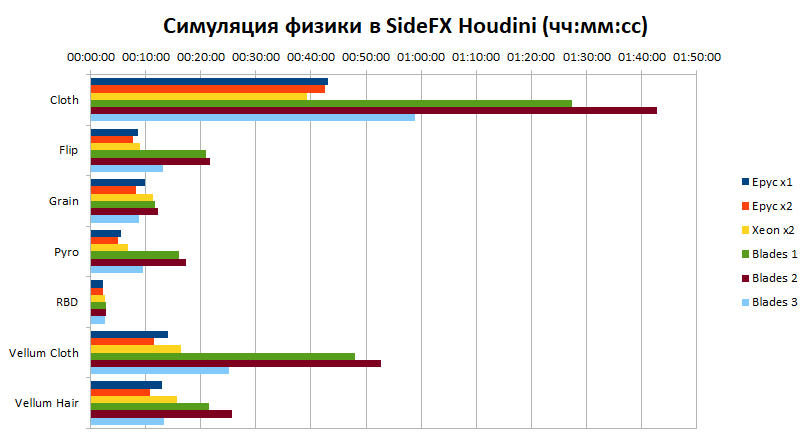
На диаграмме выше показано время, которое потребовалось узлам для вычисления каждой из симуляций вышеуказанных типов. Столь большую разницу между старыми и новыми узлами можно объяснить в большей степени архитектурными усовершенствованиями процессоров и платформ в целом, произошедшими за последнее десятилетие. Если сравнивать только современные платформы, принимая за базовый уровень результаты работы машины с Xeon, то разница уже не такая огромная, хотя и очень существенная.
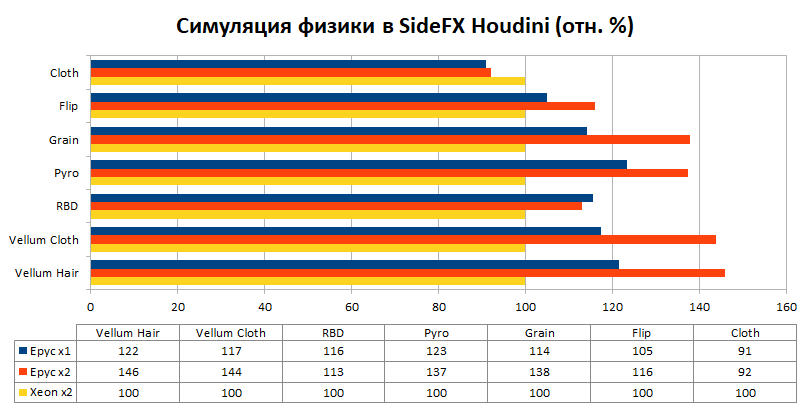
В среднем, преимущество системы на базе одного процессора AMD EPYC составляет около 20%, а системы на базе двух процессоров AMD EPYC — 30%. Решения на процессорах AMD опережают конкурентов во всех тестах, за исключением первого, который, как уже упоминалось выше, отличается тем, что математические расчеты в нем работают в однопоточном режиме. Напомним, что процессор Intel Xeon Gold 6248 имеет турбочастоту 3.9 ГГц, в то время как решения от AMD имеют только 3.35 ГГц. Вероятно, это объясняет 10% разрыв в данном тесте.
Практические тесты: моделирование и рендеринг
Тестируемые системы работали в составе рендер-фермы студии несколько недель, поэтому нам удалось собрать достаточно обширную статистику по задачам, которых за это время было обработано несколько сотен. Так как в целом распределение задач по вычислительным узлам осуществлялось автоматически, то для итогового отчета были выбраны наиболее репрезентативные задачи:с большим количеством кадров и со временем подсчета одного кадра на самой быстрой машине не менее одной минуты.
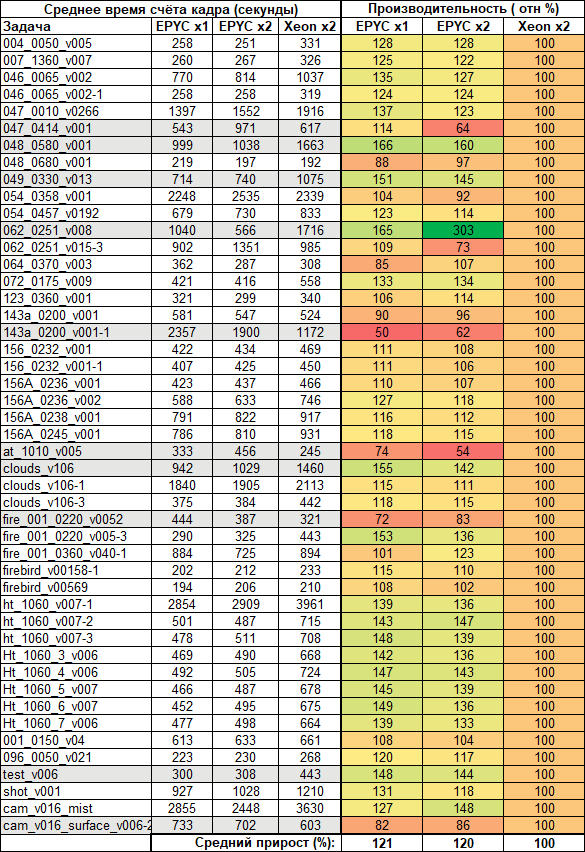
B suppressВ большинстве случаев серверы на базе EPYC оказались быстрее машин Xeon, а система EPYC с одним сокетом оказалась в среднем даже немного быстрее. В среднем, преимущество систем на базе AMD по сравнению с сервером Intel составило 20-21%. Но поскольку это реальные задачи, включающие в себя различные типы нагрузок, рост не везде одинаков. Например, в одном случае два процессора AMD оказались в три раза быстрее двух процессоров Intel, в другом — почти в два раза медленнее. Такая диспропорция является прямым следствием того, что не всегда отдельные задачи эффективно масштабируются на большое количество ядер.
В этом случае, как и в предыдущих тестах, может оказаться более выгодным распределение "нескольких задач на узел" вместо "одной задачи на узел". Для оценки обоих подходов в каждую тестовую систему был отправлен набор из 10 кадров для рендеринга. В последовательной версии каждый кадр посылался на серверы по одному, а в параллельной версии — все сразу. Результат — общее время вычислений. Тестирование показало, что двухпроцессорные серверы с AMD и Intel в этой задаче работают примерно на треть быстрее при одновременном запуске кадров для рендеринга, а однопроцессорный AMD сервер — примерно на 20%. По общей скорости работы лидируют системы с AMD.
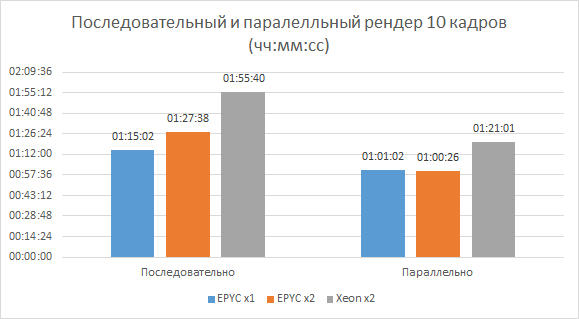
В следующем специальном тесте для более точного изучения эффективности распараллеливания была использована другая, отличная от прошлого, задача рендеринга, состоящая из восьми кадров. При этом время подсчета каждого кадра на узлах студийной фермы (Blades) обычно составляло 10-20 минут в зависимости от их производительности. Эта задача выполнялась на сервере с одним процессором AMD (EPYC x1) с настройками системы управления задачами для одновременного подсчета одного, двух, четырех и восьми кадров. Таким образом, первый вариант будет последовательным, а все остальные — параллельными.
Здесь следует обратить внимание на работу программного обеспечения для рендеринга. Одним из вариантов автоматического универсального распараллеливания его задач является разбиение целевого поля изображения на несколько блоков и вычисление каждого отдельного потока рендеринга. В общем, пользователь может выбрать для своей задачи, сколько блоков он может или должен разделить. В этом случае рендер каждого кадра не знает, что на узле считается что-то другое, и фокусируется на количестве вычислительных ядер для выбора количества запускаемых потоков для подсчета блоков.
В результате получается, что при одновременном подсчете восьми кадров уже активно используются средства процессоров и операционной системы для обработки количества потоков, значительно превышающего количество ядер. Из таблицы с результатами видно, что в этом случае можно получить неплохой выигрыш — суммарное время получения результата примерно на треть меньше, чем при последовательном подсчете всех кадров, хотя формально в обоих вариантах активно используются все процессорные ядра.
Виртуализация
Как уже упоминалось выше, для некоторых вычислительных сценариев использование одного мощного сервера с большим количеством ядер и большим объемом оперативной памяти может оказаться не очень эффективным из-за сложности управления разнородными задачами на нем. В частности, это связано с различиями в таких ресурсах, как ядра и оперативная память. Первые напрямую влияют только на скорость вычислений, но предсказать и управлять потреблением памяти гетерогенными задачами может быть просто невозможно.
В этом случае можно рассмотреть вариант "нарезки" одного "большого" сервера на несколько виртуальных с заданным выделением ресурсов. Такой подход также позволяет регулировать распределение ресурсов "на лету", выбирая оптимальный вариант для текущих задач. Для тестирования данного подхода был установлен сервер с одним процессором AMD (EPYC x1) с открытой системой управления виртуальной машиной Proxmox.
Для машины EPYC x1 — 64 ядра/128 потоков и 512 Гбайт оперативной памяти — использовались виртуальные машины (ВМ) с конфигурациями от 16 ядер и 64 000 Мбайт оперативной памяти в восемь штук до одной ВМ со 128 ядрами и 512 000 Мбайт оперативной памяти. В отличие от предыдущих тестов с реальными серверами, данный сценарий может иметь некоторые ограничения по производительности за счет размещения дисков виртуальных машин на внешнем хранилище, подключенном через NFS по сетевому соединению 10 Гбит/сек.
| Общее время счёта | ||||
|---|---|---|---|---|
| Конфигурация ВМ на EPYC x1 | 1 кадр | 2 кадра | 4 кадра | 8 кадров |
Прежде всего, следует отметить, что наилучший результат с точки зрения скорости очень мало отличается от наилучшего resполученная на реальной системе без виртуализации. Это говорит о том, что многоядерные процессоры AMD EPYC хорошо подходят для таких сценариев и могут выдерживать большие нагрузки. В то же время в виртуализации лучше всего подходит схема "8 виртуальных машин, считая каждый кадр по отдельности". В целом, можно сказать, что решения с AMD EPYC наиболее эффективны с точки зрения скорости именно в "перегруженных" сценариях, когда одновременно используется большое количество ресурсоемких задач или потоков.
Энергопотребление и плотность
Энергопотребление и энергоэффективность так же важны при оценке систем, как и их производительность. Старые блейд-системы имеют свои особенности: Шасси 4U с десятью лопастями потребляет около 3 кВт (около 260-300 Вт на узел) и требует отдельных кабелей для каждого из четырех источников питания. Тестовые системы, напротив, гораздо менее требовательны — им требуется всего два кабеля на узел 1U или 2U. Сравнение плотности и потребления современных систем и старых блейд-серверов приведено в перерасчете 4U-объёмного стоечного пространства — именно столько пространства требуется каждой доступной студийной блейд-системе.
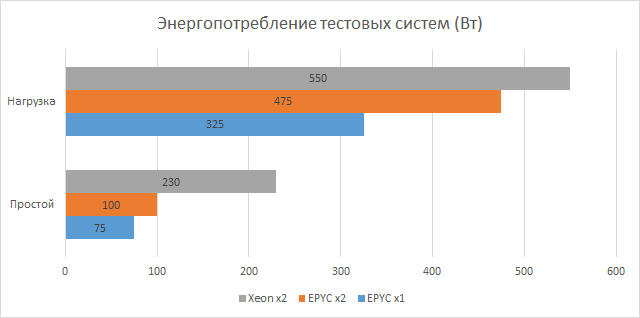
Во время тестирования на всех трех серверах был настроен удаленный мониторинг потребления с помощью встроенных в платформу датчиков. На графике выше показано максимальное и минимальное энергопотребление. Первые являются самыми высокими зафиксированными стабильными значениями под нагрузкой, а вторые были получены, когда серверы не находились под нагрузкой. Более высокая эффективность решений AMD, вероятно, частично объясняется более тонким процессом.
| Общее время счёта | ||||
|---|---|---|---|---|
| Конфигурация ВМ на EPYC x1 | 1 кадр | 2 кадра | 4 кадра | 8 кадров |
Однопроцессорная 1U система с AMD EPYC 7702 представляет наибольший интерес с точки зрения плотности ресурсов. Четыре из этих систем предлагают 256 ядер с общим потреблением около 1.3 кВт. В то время как старая блейд-система (Blades 3) в шасси 4U имеет 160 ядер и, как упоминалось выше, потребление 3 кВт. То есть, современное решение AMD имеет в 1,6 раза больше ядер с более чем вдвое большей разницей в потреблении.
| Примерная стоимость конфигураций, $ | |||
| EPYC x1 | EPYC x2 | Xeon x2 | |
| Процессоры | 7 435 | 2 × 2 185 | 2 × 3 050 |
| Шасси | 2 100 | 3 070 | 2 350 |
| Память | 8 × 320 | 16 × 320 | 12 × 299 |
| Итого | 12 095 | 12 560 | 12 038 |
Две двухпроцессорные 2U системы с AMD EPYC 7402 оказались чуть менее плотными: 96 ядер при потреблении 950 Вт, т.е. в 1,66 раза меньше ядер и более чем в три раза меньше расхода по сравнению с 4U лопаткой (Blades 3). Наконец, для тестовой системы с Intel Xeon Gold 6248 при тех же условиях сравнения мы получаем в два раза больше ядер и чуть менее чем в три раза меньше разницы в энергопотреблении.
Кроме того, тестовые серверы 1U/2U менее интенсивно охлаждаются по сравнению с лопастями и могут быть модернизированы с помощью GPU (при условии, что платформа поддерживает эту возможность), что может ускорить некоторые вычисления или быть использовано для организации VDI. Если такая универсальность не нужна и требуется еще большая плотность, можно использовать узлы 2U4N.
A>Ценность
Стоит сразу сделать оговорку, что расчет стоимости тестовых платформ является приблизительным, так как обычно такие закупки намного сложнее и учитывают весь проект, а не отдельные машины. ASBIS, предоставившая серверы для тестирования, также предоставила цены на каждую из базовых платформ (процессор + память + шасси) в случае разовой закупки. Естественно, если будет закуплено больше машин, цены будут отличаться.
| Примерная стоимость конфигураций, $ | |||
| EPYC x1 | EPYC x2 | Xeon x2 | |
| Процессоры | 7 435 | 2 × 2 185 | 2 × 3 050 |
| Шасси | 2 100 | 3 070 | 2 350 |
| Память | 8 × 320 | 16 × 320 | 12 × 299 |
| Итого | 12 095 | 12 560 | 12 038 |
Стоимость всех трех платформ имеет одинаковый порядок. Обе AMD-системы в тестах на реальных нагрузках оказались практически идентичны по производительности и заметно быстрее сервера с Xeon. Однако, учитывая более высокую плотность и энергоэффективность, именно односокетная система AMD является наиболее выгодной.
Если сравнить фактически протестированные системы с теоретически более подходящими (Xeon Gold 6248R, EPYC 7702P и 7F72), то картина становится еще более интересной. Ценовая политика AMD для процессоров серии P, которые подходят только для односокетных систем, направлена на вытеснение двухсокетных конфигураций Intel — при более низкой стоимости процессора можно получить более высокую плотность и/или количество ядер. А это касается еще более "простых" моделей, без повышенной частоты и огромного кэша, как в 7Fx2.
| Процессоры, 1ku RCP $ | |||
|---|---|---|---|
| EPYC x1 | EPYC x2 | Xeon x2 | |
| Тестируемый вариант | 6 450 | 2 × 1 783 | 2 × 3 075 |
| Оптимальный вариант | 4 425 (7702P) | 2 × 2 450 (7F72) | 2 × 2 700 (6248R) |
В то же время, AMD сознательно не сегментирует процессоры по всем остальным параметрам: любой EPYC 7002 имеет 8 каналов памяти DDR4-3200 и 128 линий PCIe 4.0, в отличие от 6 линий DDR4-266/2933 и 48 линий PCIe 3.0 у Intel. А двухпроцессорные системы AMD могут понадобиться уже для обеспечения более высокой базовой частоты на количество ядер, если в случае HPC/AI систем объем памяти на одно ядро составляет более 4 терабайт, при определенных требованиях к емкости и пропускной способности.
⇡#Включение
один из te основные выводы, которые студия сделала для себя по результатам тестирования, касаются не аппаратного, а программного обеспечения. Точнее, она полностью совместима с платформами AMD. Все программные пакеты, используемые CGF, работали без проблем и дополнительной тонкой настройки. В том числе и в более сложных блочных и виртуализированных сценариях рендеринга. Именно страх перед программной несовместимостью до сих пор является одним из психологических, не всегда разумных барьеров в выборе аппаратного обеспечения. Также не было проблем с совместимостью при установке дополнительных сетевых адаптеров или дисков.
С аппаратным обеспечением стратегия компании AMD по продвижению систем с одним разъемом в случае студии достигла своей цели. Тестовые платформы имеют один порядок стоимости и намного быстрее, чем старые блейд-системы, но двухсокетная система AMD все еще несколько дороже остальных. В то же время, обе платформы AMD в реальных студийных задачах симуляции и рендеринга в среднем на 20-21% быстрее, чем системы на базе Xeon. Если учесть, что использование P-версии процессора в односокетном AMD-сервере еще больше снизит стоимость, то становится очевидным, что эта платформа является наиболее привлекательной с точки зрения соотношения цены и производительности среди всех протестированных.
Кроме того, по сравнению с другими тестовыми платформами и старыми блейд-системами она более энергоэффективна и более плотна по количеству ядер. Упрощение прокладки кабелей и снижение счетов за электроэнергию, несомненно, являются очень важными аспектами для студии. Сочетание всех этих факторов привело к тому, что еще до завершения всех тестов в рендер-ферме студия приобрела еще один односокетный сервер на базе AMD EPYC 7002 для изучения его возможностей в других сценариях IT-задач компании.
По результатам тестирования студия рассматривает возможность частичного обновления рендер-фермы, пока без окончательного отказа от блейд-систем, за счет использования однопроцессорных платформ AMD высотой 1U, но в конфигурации, отличной от тестовой системы. Основным фактором по-прежнему остаются финансы, так как экономика студии в значительной степени привязана к требованиям выполняемых заказов — чем сложнее с технической точки зрения проекты, тем выше требования к "железу".
В сложившейся ситуации возникает потребность в небольшом, относительно недорогом, но достаточно быстром и универсальном кластере для повседневных студийных нужд. В частности, для тестирования новых технологий и возможностей. Отдельные сверхтяжелые по совокупности многих факторов задачи проектов чаще всего экономически выгоднее "выгружать" на внешние площадки — большие кластеры или облака.
*"Сколько висеть в ядрах? Наиболее оптимальными для нас сейчас являются системы 1U с 32-ядерными процессорами AMD EPYC 7502P (2.5-3.35 ГГц, L3-кэш 128 Мбайт, TDP 180 Вт). Они обеспечивают баланс между стоимостью, включая шасси и память, плотностью, энергопотреблением, производительностью и универсальностью для обеспечения эффективной работы студии в современных условиях", — заключает технический директор CGF